MVS環境でデータセットを作ってみる
こんにちは、今日はMVS環境でデータセットを作成してみようと思います。
データセットとは、WindowsやLinuxにおける「ファイル」にあたるものですが、その考え方や扱い方は大きく違います。
この記事では、代表的なデータセットの種類と、ISPFのメニューからデータセットを作成する方法を解説します。
※データセットの作成は、「アロケーション」と呼ばれます。
今更!自宅にメインフレーム構築 (MVS on Linux)
まずは、↑の記事で構築したMVS環境を起動していきます。
ステップ1: herculesとmvsのIPL
MVS環境のIPLをしていきます。
IPLとは
Initial Program Loadのことで、OSを起動するためのプログラムを読み込み、CPUに実行させることで、業務では、他の必要なミドルウェアなども含めて起動し、システム稼働させることまでの一連の手順をIPL手順と言ったりします。
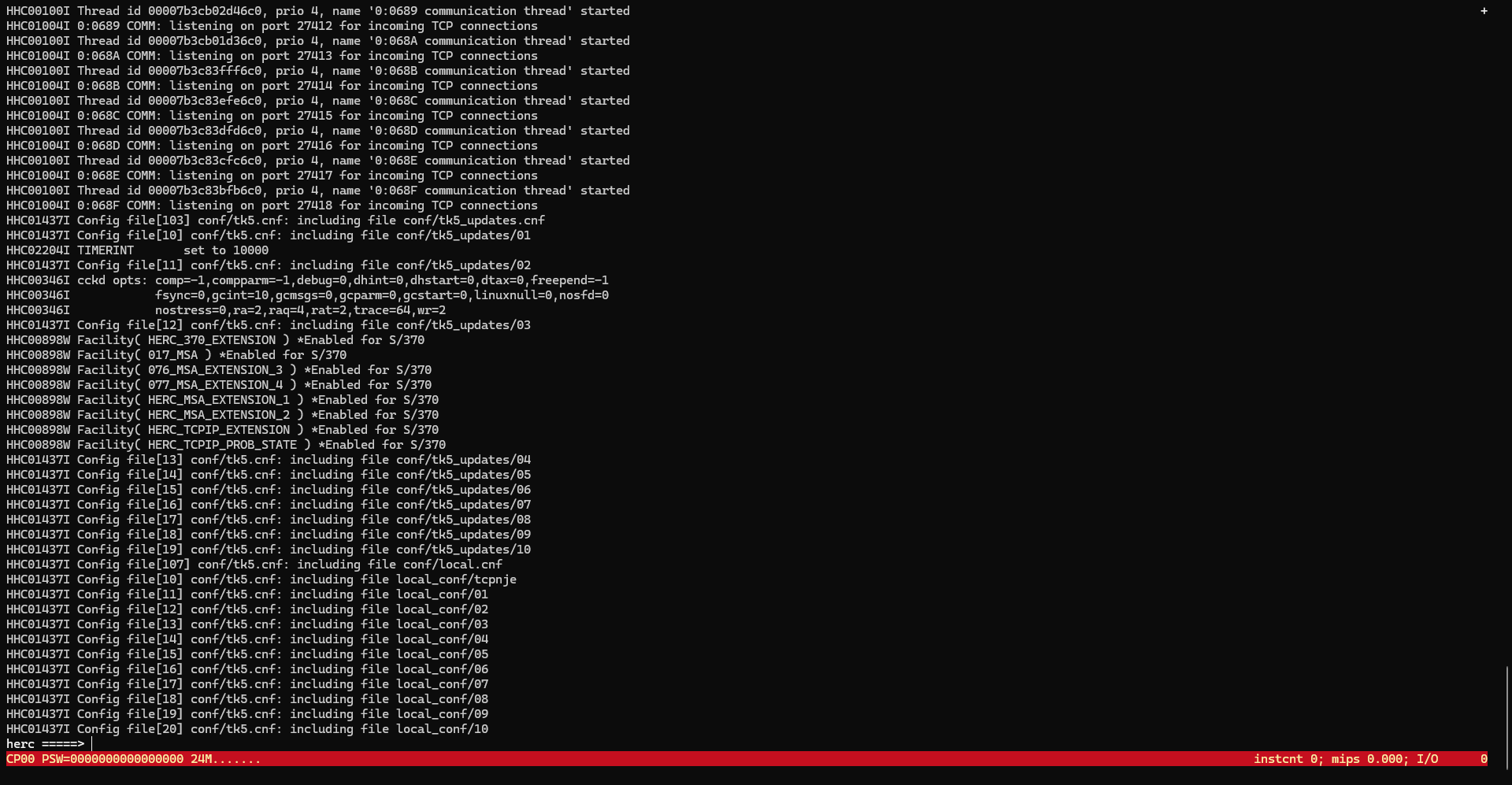
以下のコマンドでherculesコンソールを起動していきます。
hercules -f conf/tk5.cnf
画像のように、herc =====> が表示されればOKです。
次に以下のコマンドを入力します。
ipl 390
以下のメッセージが表示されたらOKです。
IEA101A SPECIFY SYSTEM PARAMETERS FOR RELEASE 03.8 .VS2
メッセージが確認出来たら、以下のコマンドを入力します。
/r 00
以下のメッセージが表示されたらIPL完了です!
MVS038J MVS 3.8j TK5 system initialization complete CN=00
試しに、IPL後にどのようなプログラムが動いているか確認してみましょう。
herculesコンソールに以下のコマンドを入力します。
/d a,l
d a,l
/ 7.12.36 IEE102I 07.12.36 25.223 ACTIVITY 458
/ 00009 JOBS 00006 INITIATORS
/ CMD1 CMD1 CMD1 V=V
/ BSPPILOT BSPPILOT C3PO V=V S
/ JES2 JES2 IEFPROC V=V
/ NET NET IEFPROC V=V
/ TP TP TCAM V=V
/ MF1 MF1 IEFPROC V=V S
/ TSO TSO STEP1 V=V S
/ SNASOL SNASOL SOLICIT V=V
/ JRP JRP JRP V=V S
/ 00000 TIME SHARING USERS
/ 00000 ACTIVE 00040 MAX VTAM TSO USERS
herc =====>
主要なものについて、説明します。
| CMD1 | MVS環境において、オペレーターが入力したコマンドを処理するプログラム |
| JES2 | Job Entry Systemの略で、ジョブの入出力を管理するプログラムです。 カードリーダーやSUBMIT時のジョブ入力、実行、スプーリング、(プリンタやファイルへの)出力を担当します。 |
| TP | TP (Teleprocessing) や TCAM (Telecommunications Access Method) は、オンラインシステムや端末通信を管理するプログラムです。 |
| TSO | Time Sharing Optionの略で、対話型オンライン機能を提供するプログラムです。 ユーザーは端末からコマンドを入力し、即座に結果を得ることができます。バッチ処理とは異なり、複数のユーザーが同時にシステムを利用できます。 |
| SNASOL | SNA (Systems Network Architecture) は、IBMの通信プロトコルです。SNASOL は、SNA環境におけるセッション確立や接続管理を行うためのプログラムです。 |
次に、TSOからログインしていきます。
ステップ2: TSOへのログオン
次はTSOでログインしていきます。
今回は、x3270という無料の3270コンソール画面を提供するフリーウェアをインストールしたので、それを使ってリモートログインしてみます。
インストールすると、Program Filesにwc3270というフォルダができるので、その中にあるwc3270.exeを起動します。
すると、ターミナルが開くので、以下のコマンドを入力することでアクセスできます。
(実際のIPアドレスに置き換えてください。ポート番号はデフォルトで3270です。)
connect <IPアドレス>:<ポート番号>
その後、以下のような画面が表示されればOKです。
そのまま、TSOと入力してEnterを押しましょう。
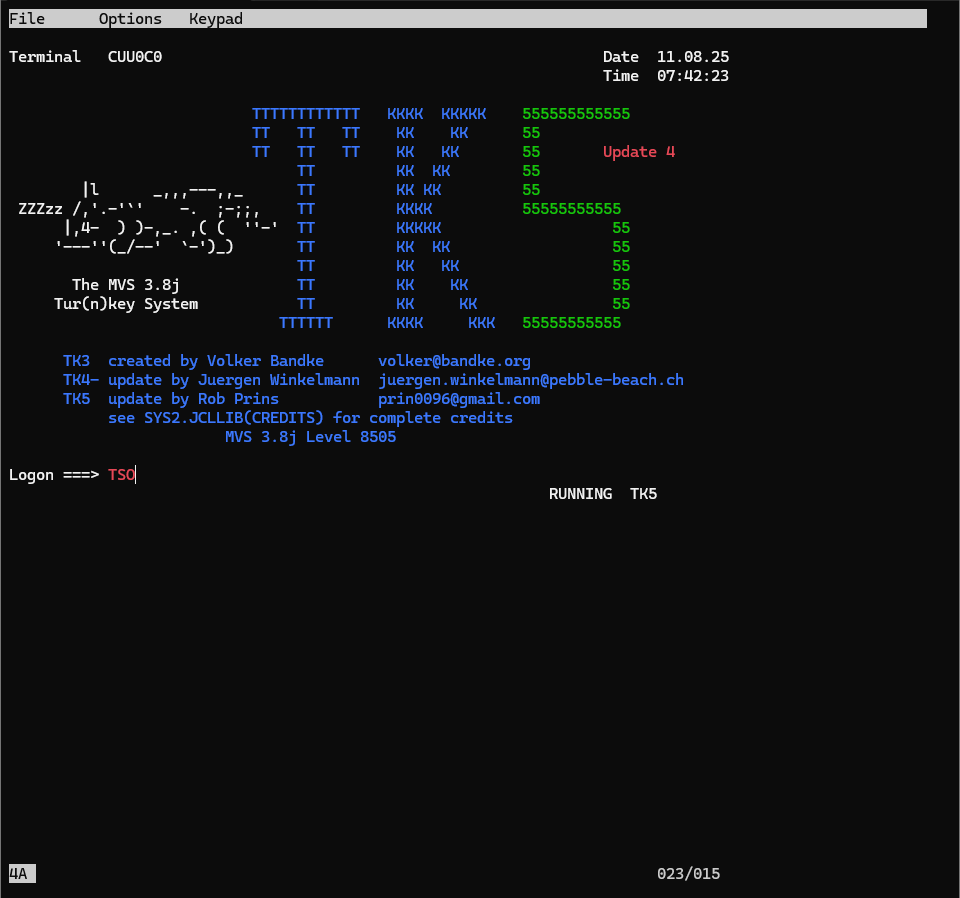
IKJ56700A ENTER USERID -
上記のメッセージが表示されたら、"HERC01"と入力しましょう。
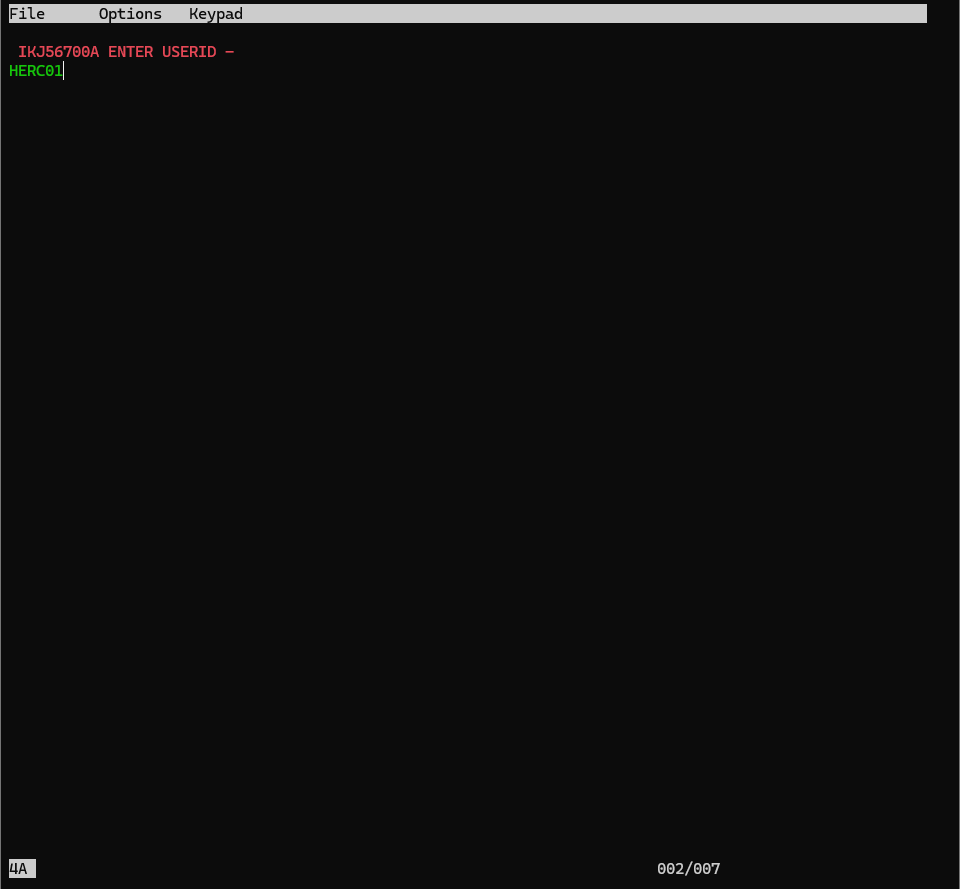
ENTER CURRENT PASSWORD FOR HERC01-
と表示されるので、"CUL8TR"と入力しEnterを押しましょう。
Piano Manの歌詞とジョークめいた内容が表示されます。
Enterを押しましょう。
ISPF(Interactive System Productivity Facility)のメニュー画面が表示されます。
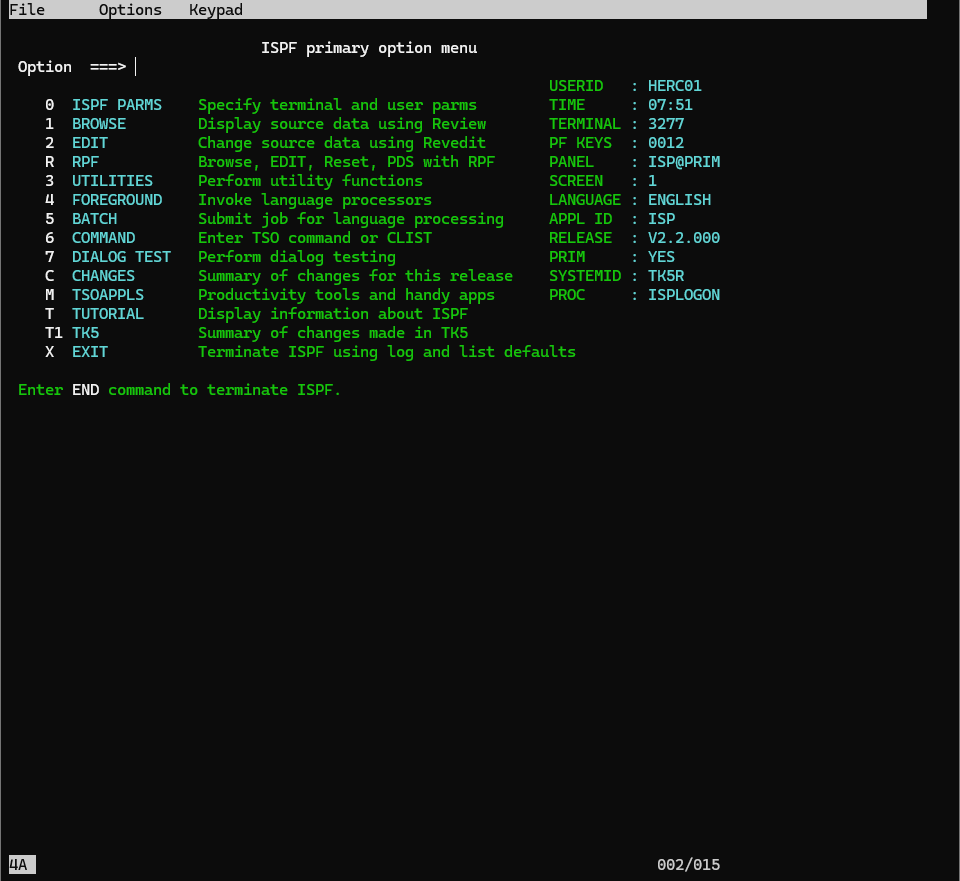
ちなみに、この時herculesコンソールのsyslogを確認すると、HERC01ユーザーでログインが行われたというログが表示されます。

ステップ3:ボリュームシリアルの確認
データセットを作成する前に、どのボリュームにデータセットを作成するかを決める必要があります。
ボリュームとは、メインフレームにおける記憶媒体装置で、WindowsでいうCドライブや、USBを接続したときのリムーバブルディスクのようなものと思ってください。
データセット作成時は、どの記憶媒体に作成するかを指定する必要があります。
herculesコンソール画面で以下のコマンドを入力します。
/d u,dasd,online
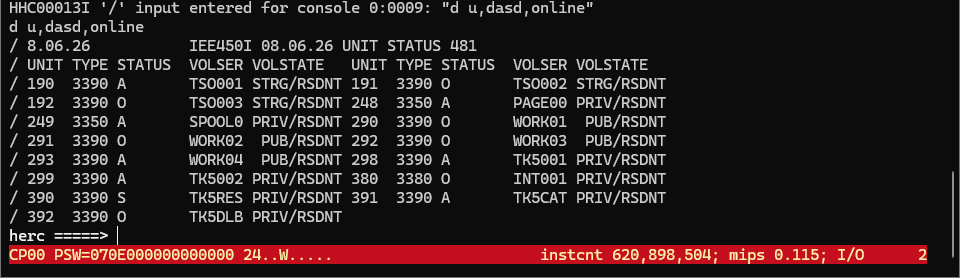
WORK02が作業用ボリュームっぽいのでこのボリュームにデータセットを作成することにしましょう。
ステップ4:順次データセットの作成
ボリュームシリアルが確認できたので、まずは順次データセットとというものから作成していきます。
MVSでのデータセット作成は"アロケーション"といいます。
以降、アロケーションと呼びます。
各データセットの種類と解説は、本記事の最後に行います。
ISPFのメインメニューからアロケーションを行うためのメニューを選択していきます。
メニューは、数字で指定し、Enterを押すことで画面遷移します。
もし、手順とは違うメニューを選んでしまった場合は、F3(PF3)を押すことで前の画面に戻れます。
以下に手順を記載します。
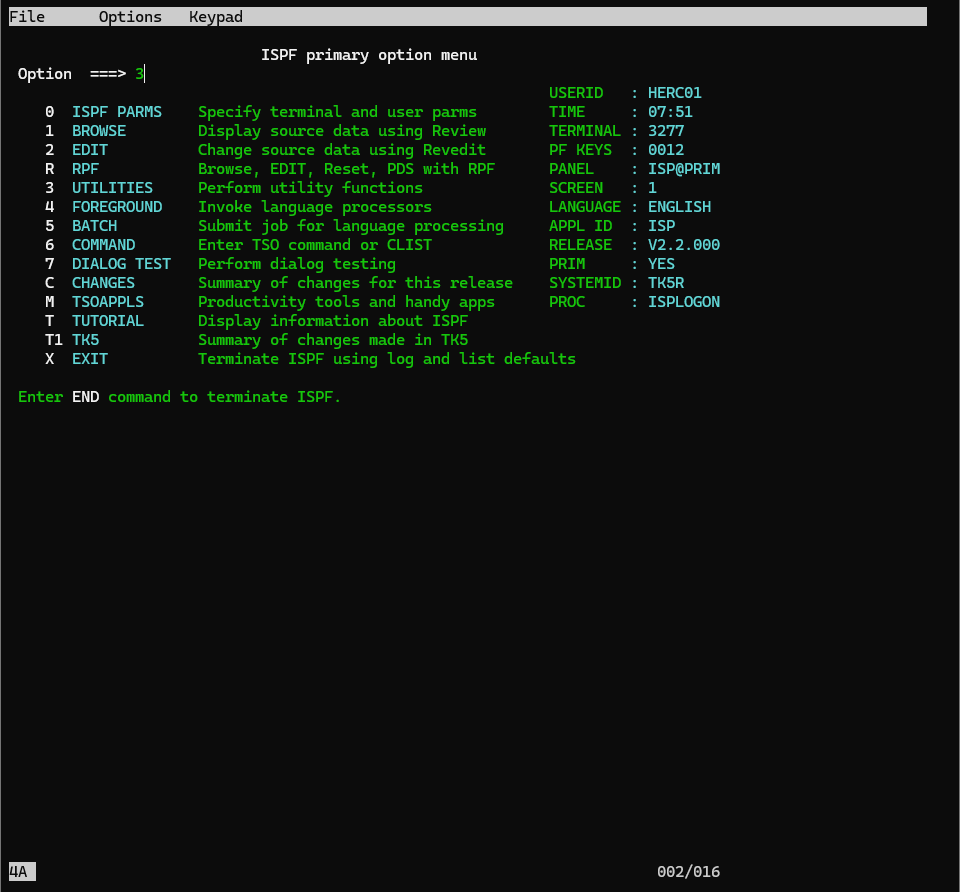
1.ISPF のメインメニューから '3' (Utilities) を選択し、Enterキーを押します。
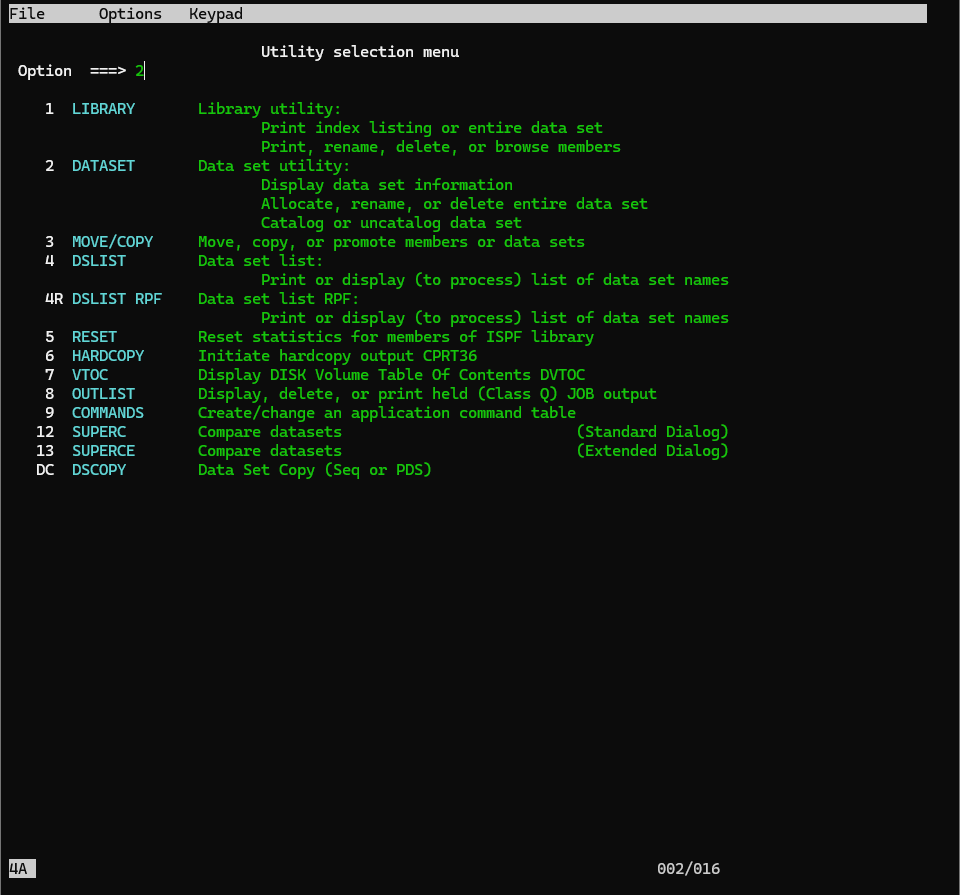
2.ユーティリティメニューから '2' (Dataset) を選択し、Enterキーを押します。
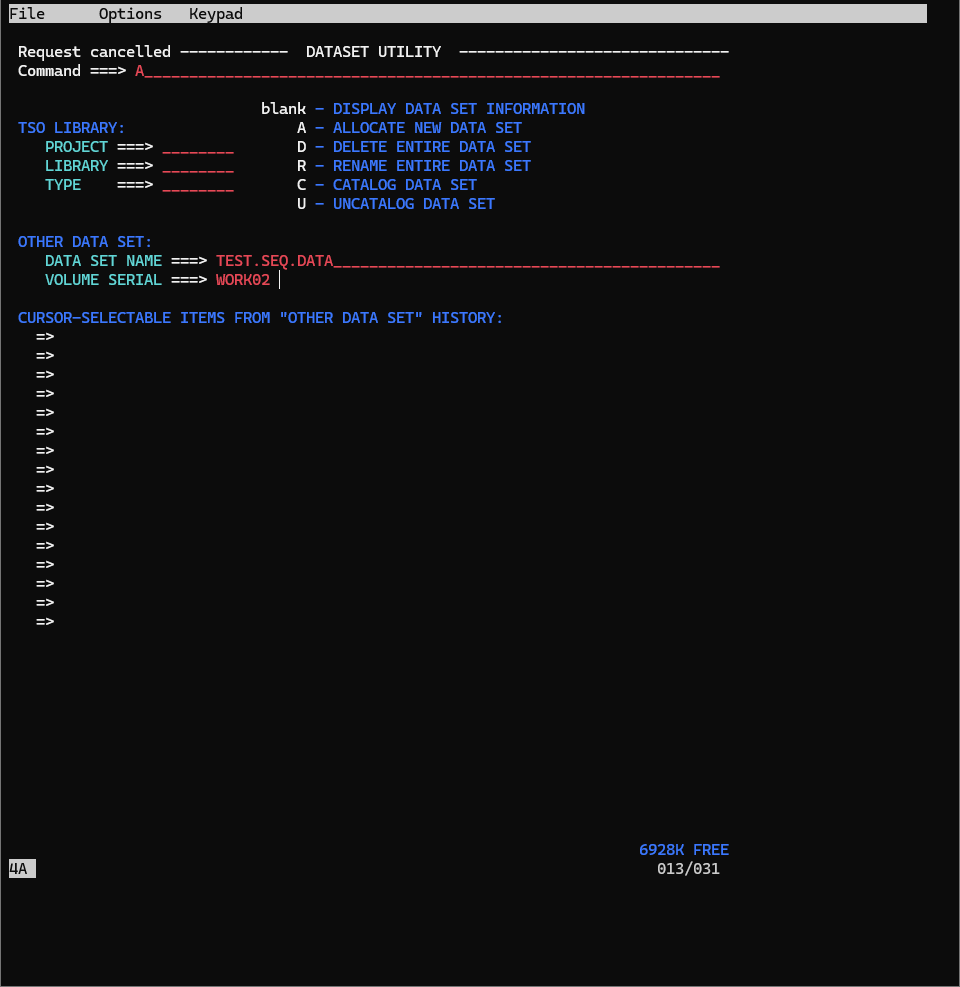
3.データセットユーティリティパネルでCommand欄に 'A' (Allocate) を入力した状態で、以下の情報を入力します。
入力欄のカーソル移動にはTabを使います。
| DATA SET NAME | TEST.SEQ.DATA |
| VOLUME SERIAL | WORK02 |
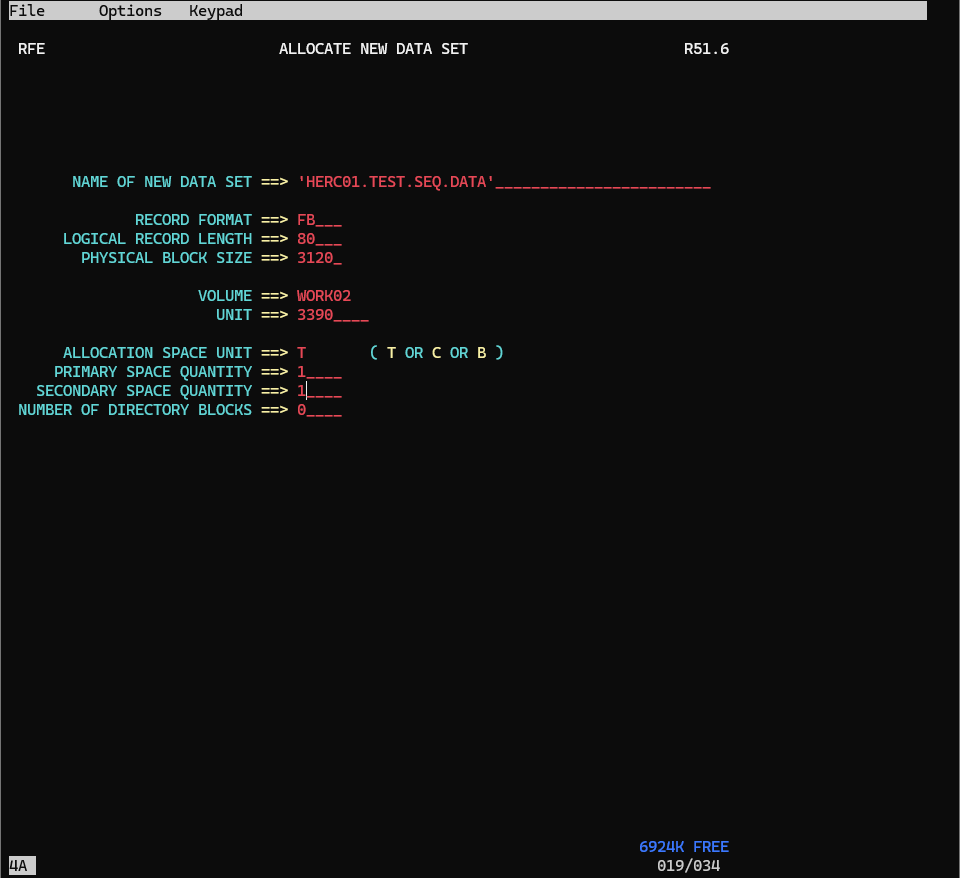
4.Allocate New Data Set パネルで、以下の情報を入力します。
※ここに記載がないものは、ブランクで問題ないです。
Name: `HERC01.TEST.SEQ.DATA` →入力済
Record Format: FB
Logucal Record Length: 80
Physical Block Size: 3120
Volume Serial: WORK02 →入力済
UNIT: 3390
Allocation Space Units: C
Primary Space Quantity: 1
Secondary Space Quantity: 1
Directory Blocks: 0
※Directory Blocksは順次データセットのため、0を指定します。
5.設定が完了したら、Enterキーを押してデータセットを作成します。
上記手順を進めると、DATASET UTILITYの画面に戻るので、Command欄に「start」と押して、新しい画面を開きましょう。
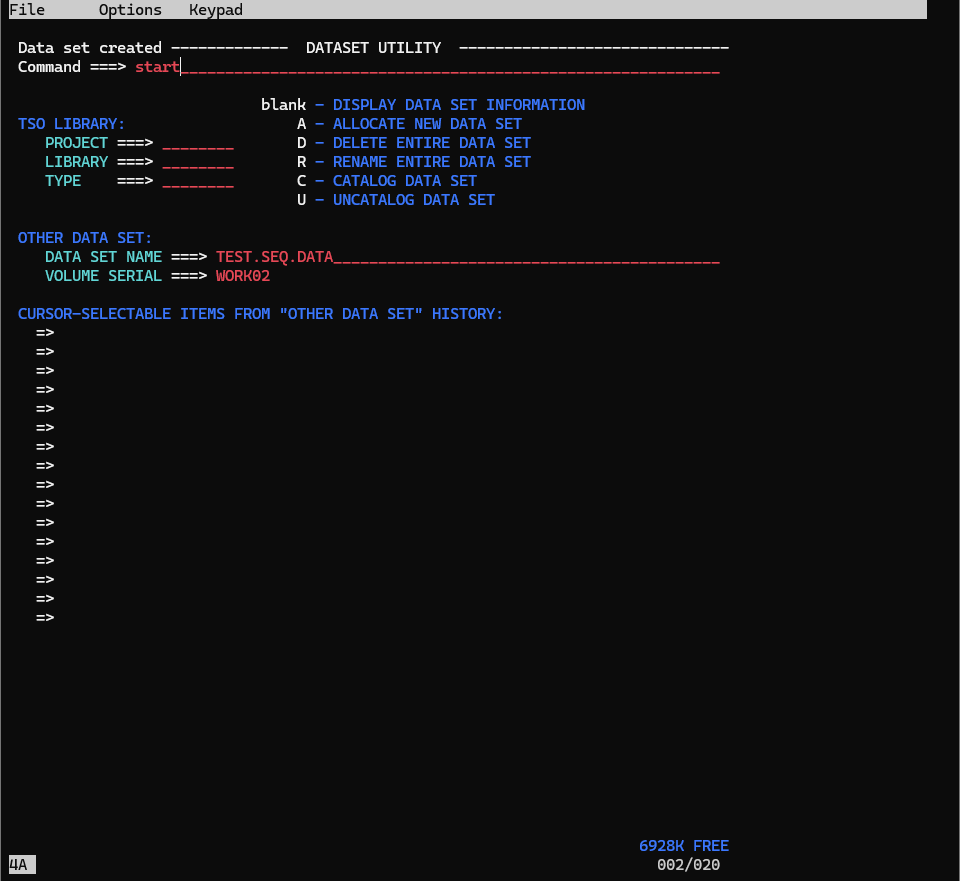
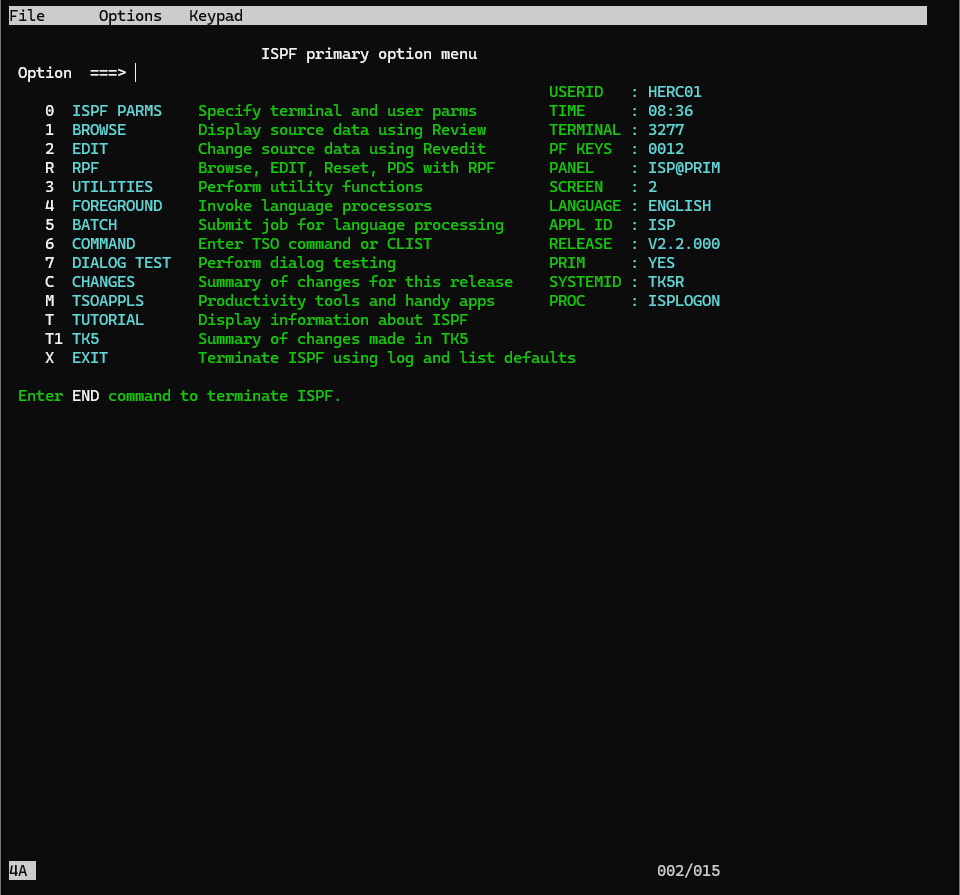
startを押すと、2つ目の画面が開きます。
先ほど開いていた画面には、F9を押すことで戻ることができます。
さらにF9を押すと2つ目の画面に戻ります。
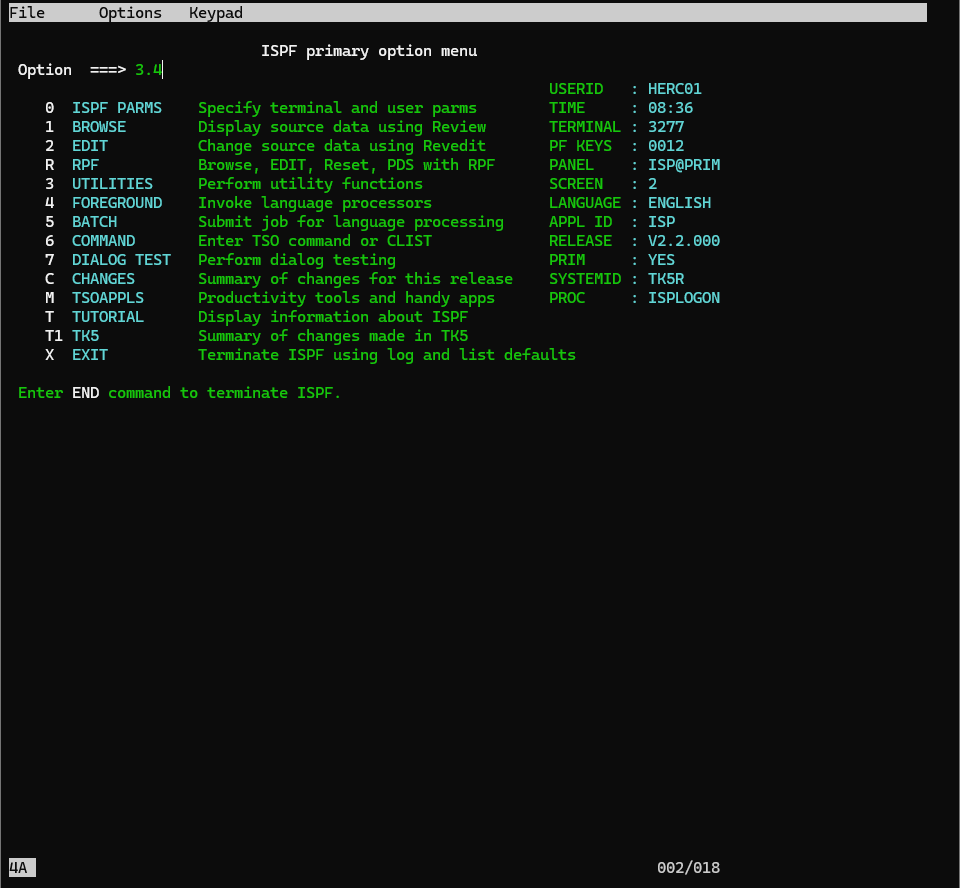
ISPFの最初の画面で、3.4と入力し、データセット確認画面を開きましょう。
先ほどは、順番に3(UTILITES)、2(DATASET)と選択しましたが、ピリオドを挟むことで短縮できます。
今回は3(UTILITIES)の後に4(DSLIST)を確認したいので、一気に開いてみましょう。
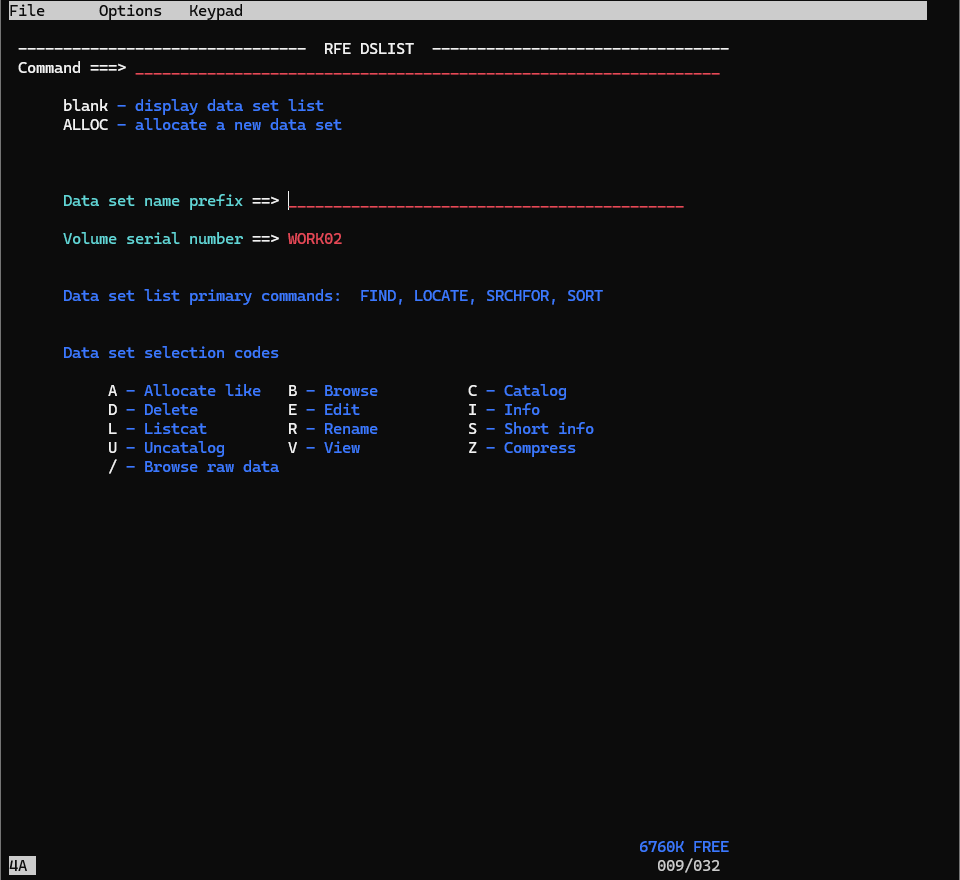
ここからデータセットを確認することが可能です。
(もちろん、他にも色々方法はありますが)
では、Data set name prefixに先ほど作成したデータセット名を入力し、Enterを押しましょう。
Data set name prefix = HERC01.TEST.SEQ.DATA
Volume serial numer = WORK02
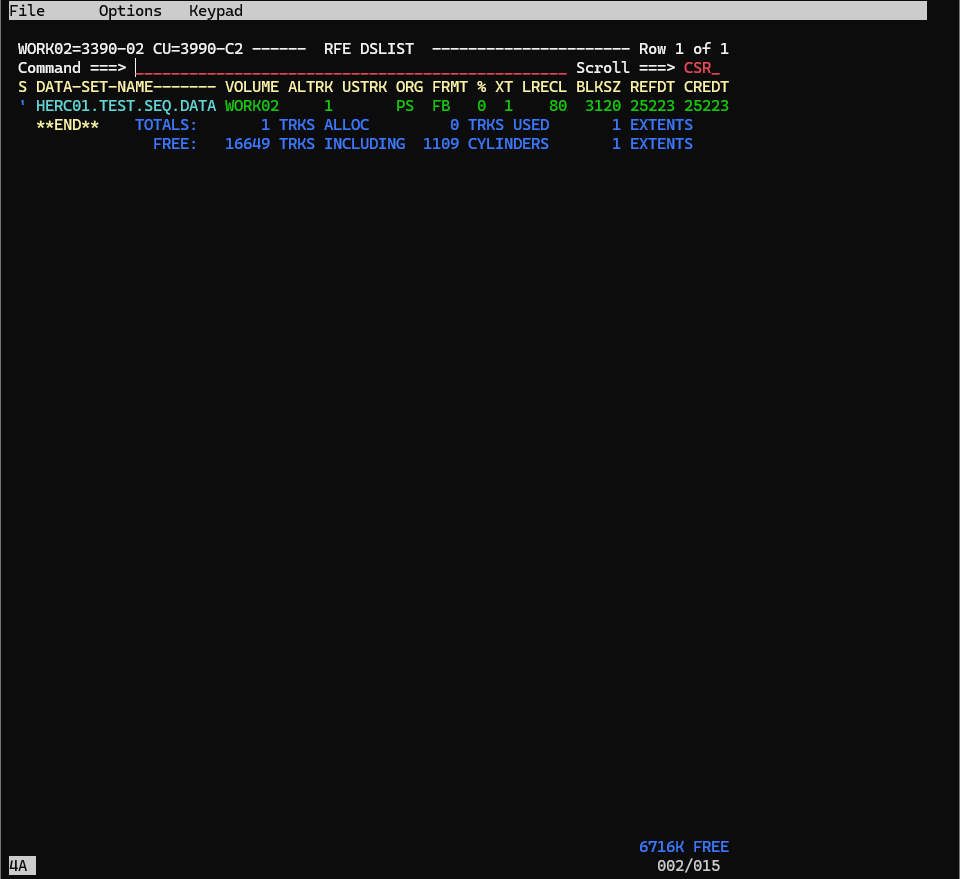
先ほど作成したデータセットが表示されました。
試しに、なにか書き込んでみましょう。
tabでカーソルをデータセット名の左に持っていき、eと入力してEnterを押してみましょう。
※eはeditの意味です。、他には、b(browse)、d(delete)などの1文字コマンドがあります。
すると、以下のような画面が表示されます。
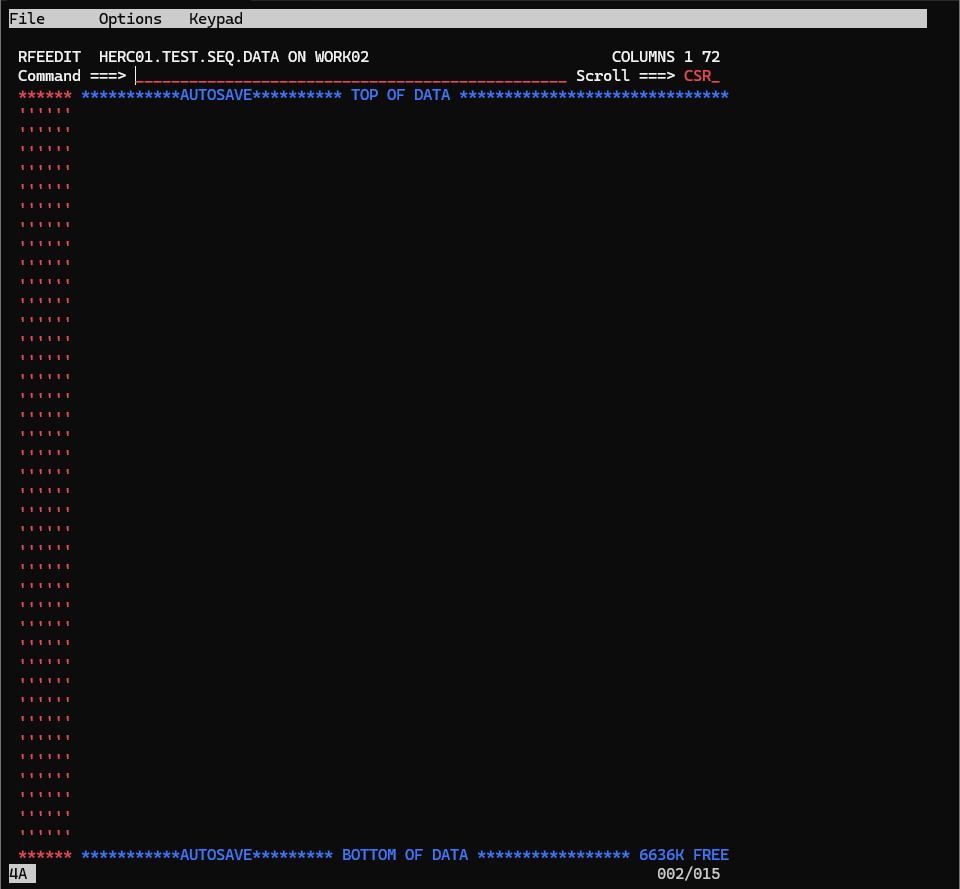
適当に何か入力して、Command欄にsaveと入力してEnterを押してみましょう。
Data Savedと表示されればOKです。
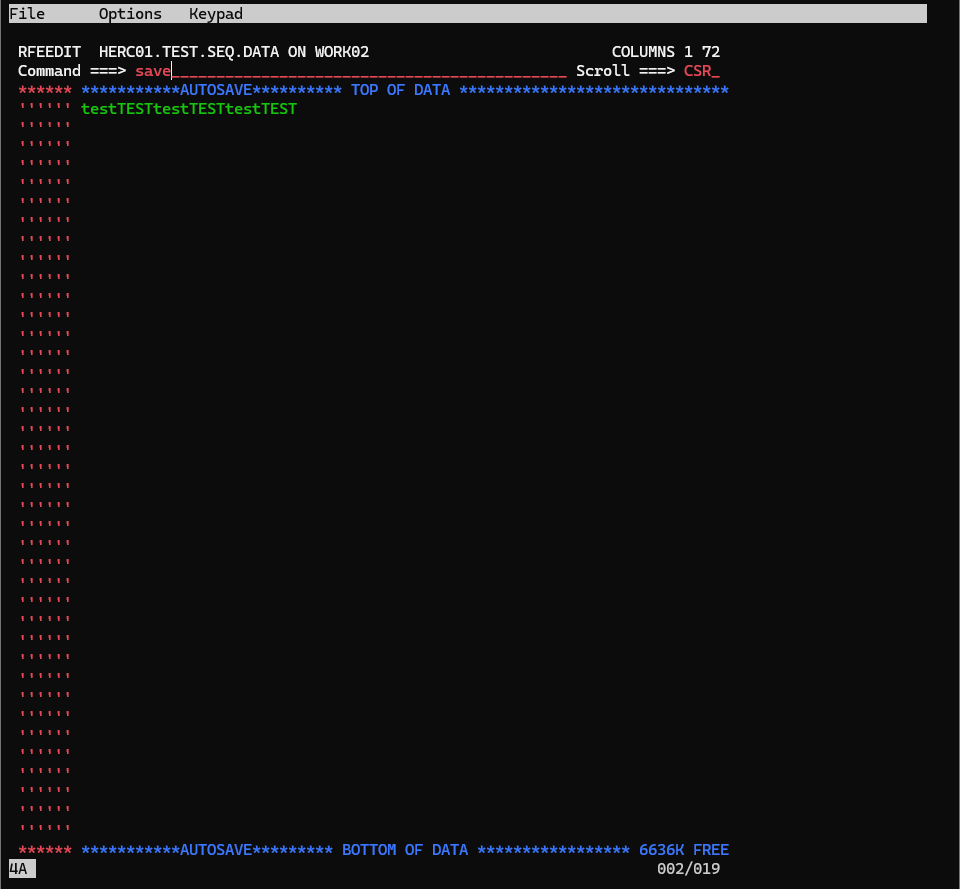
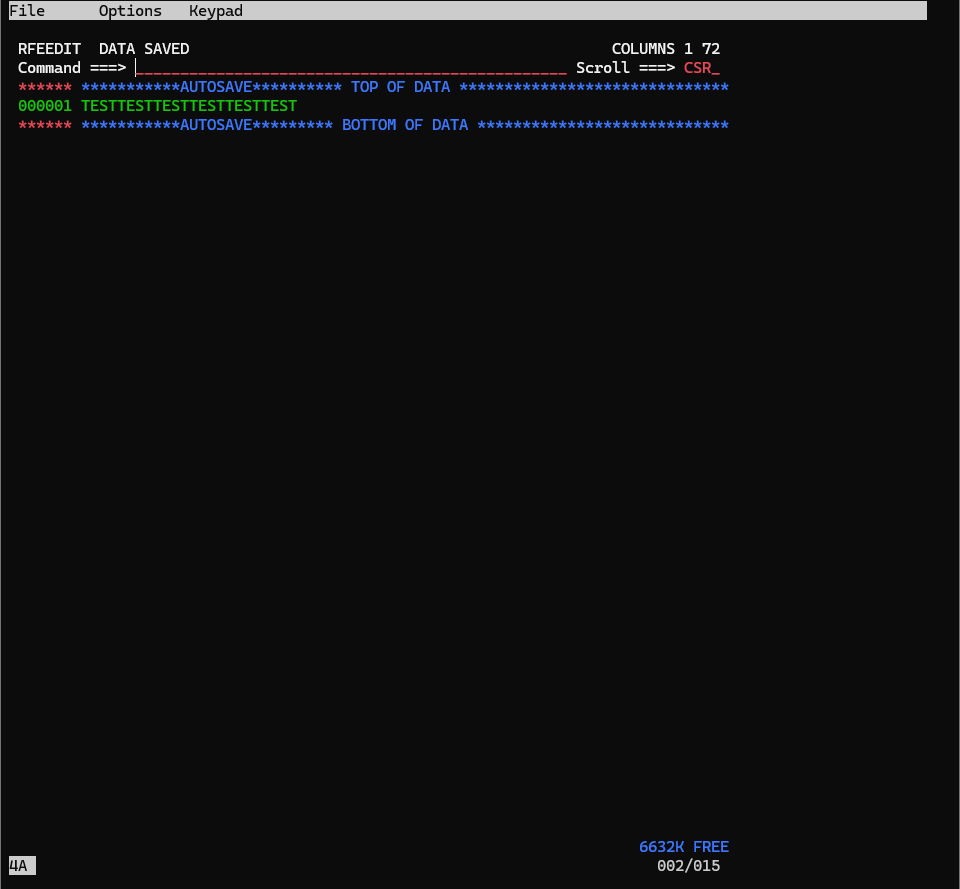
F3ボタンを押して、エディタ画面を抜けましょう。
その後、bでデータセット内をブラウズしてみましょう。
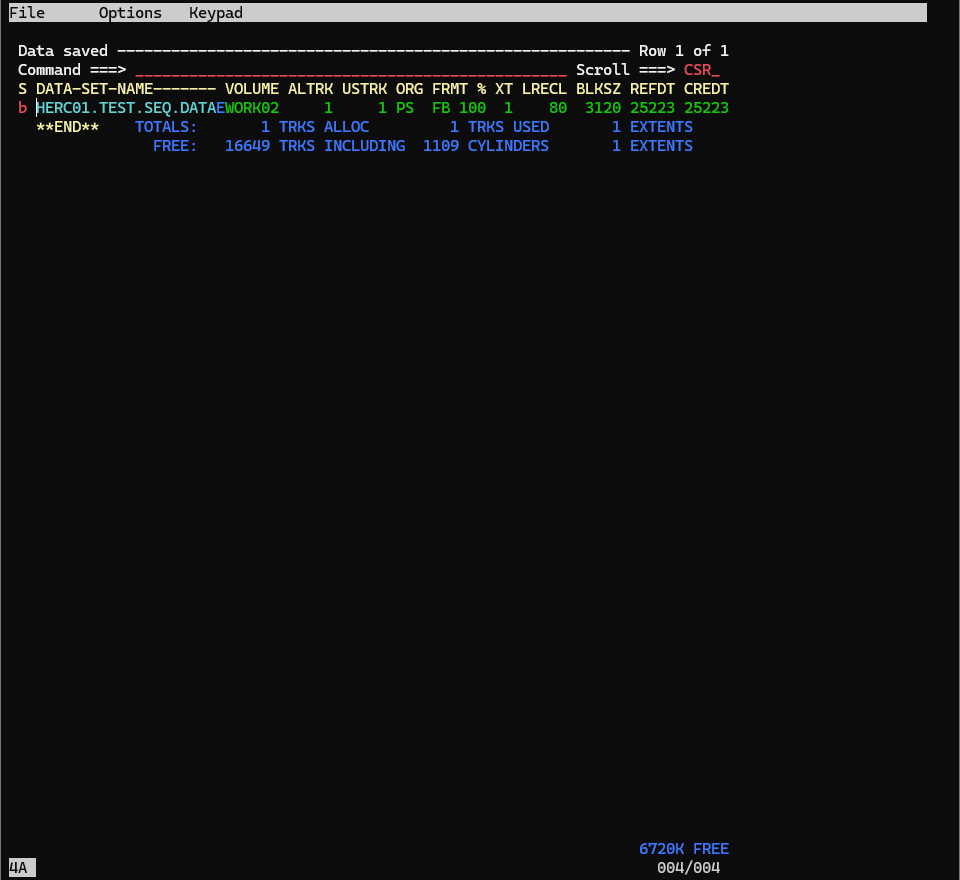
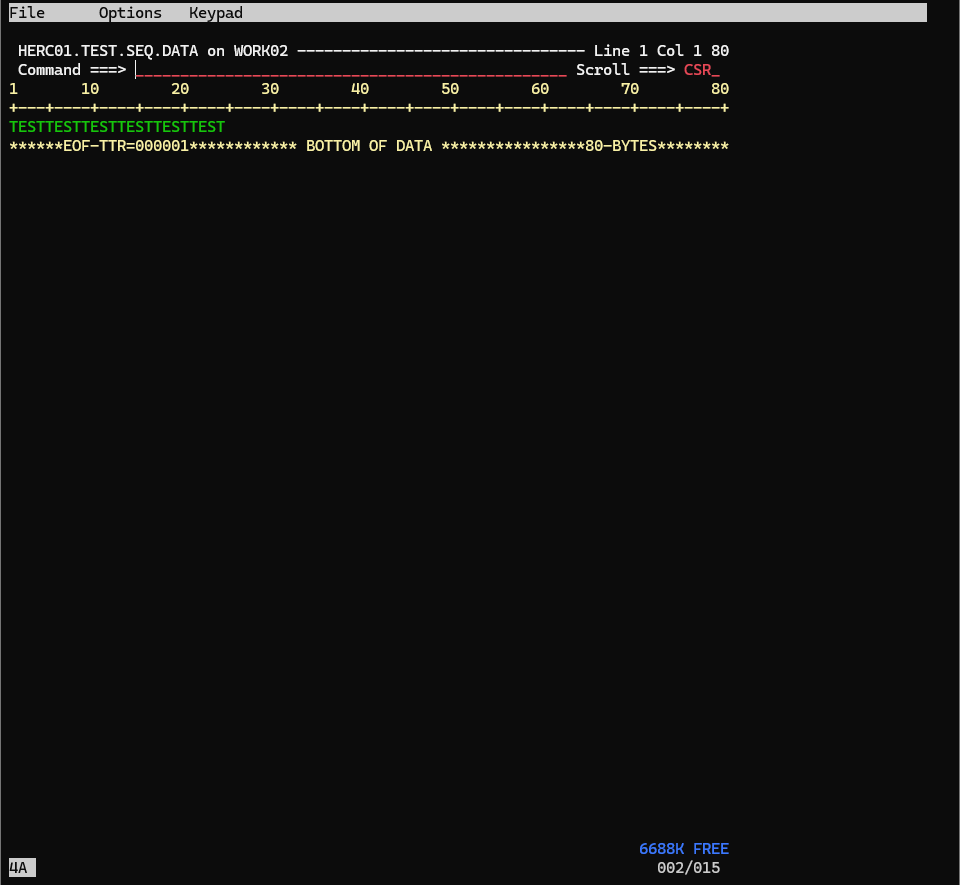
入力された文字がちゃんと保存されたのがわかると思います。
saveの時にすべて大文字になっていますが、これはMVS環境の仕様によるもので、初期のメインフレームがパンチカードを入力媒体にしていたことに由来する習慣で、多くのシステムプログラムが大文字を扱うことを前提としています。
MVSの世界は継承の世界ということで、それまで使えていた古いシステムやユーティリティプログラムは、いくらバージョンアップしようが利用できるようにする、という強固な思想の元このような仕様がよく残っています。
さて、これで順次データセットの作成は完了です。
次は、区分データセットを作成していきます。
ステップ5: 区分データセットの作成
では、データセットをブラウズしている画面から、F9を押して、再度アロケーションするための画面を開きます。
1.順次データセットを作成したときと同じように、データセットユーティリティパネルでCommand欄に 'A' (Allocate) を入力した状態で、以下の情報を入力します。
入力欄のカーソル移動にはTabを使います。
入力後、Enterを押します。
| DATA SET NAME | TEST.PDS.LIB |
| VOLUME SERIAL | WORK02 |
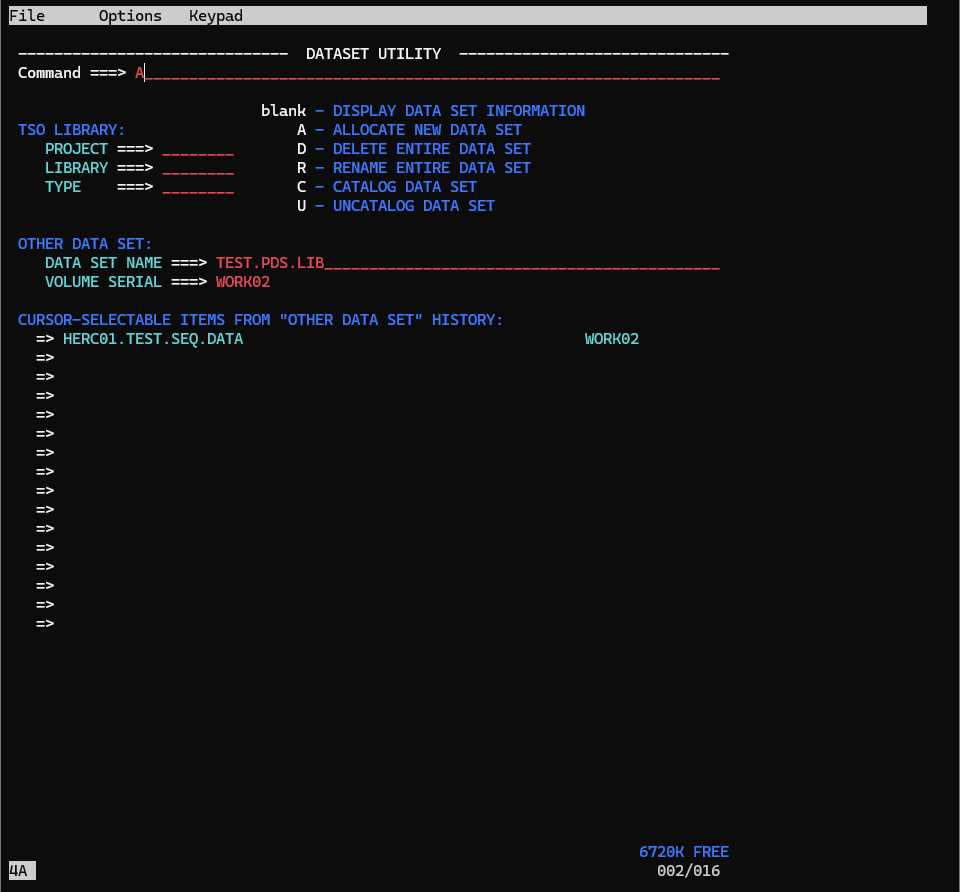
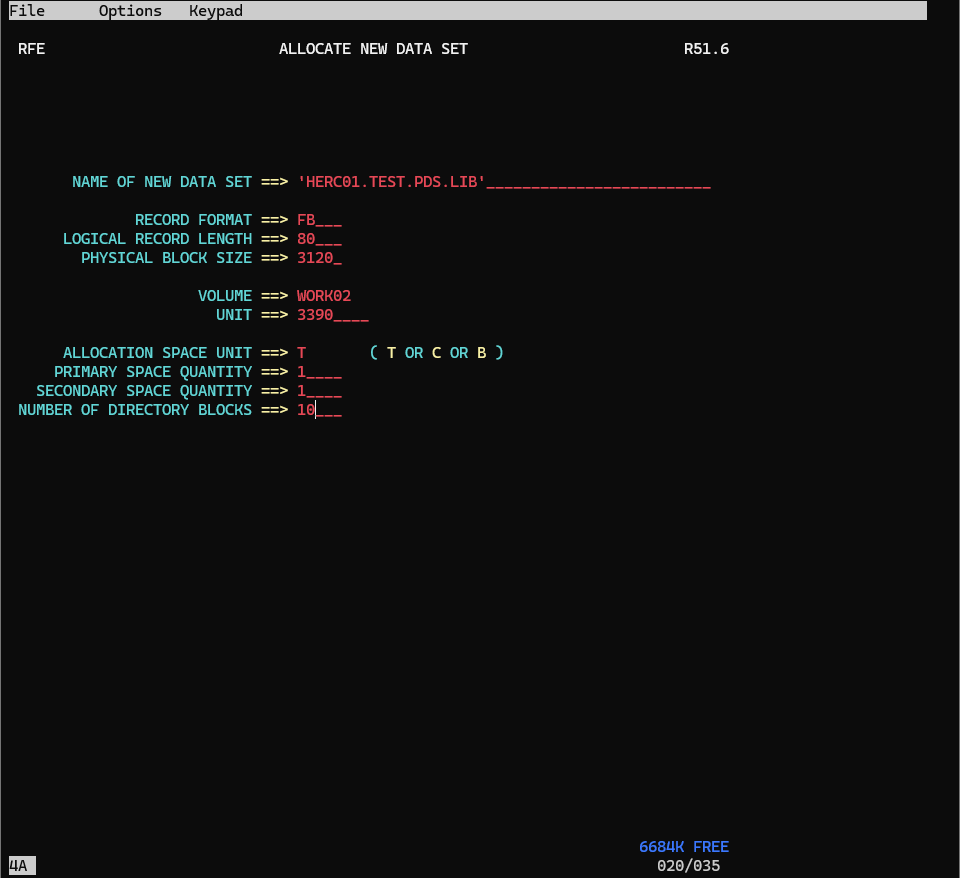
2.Allocate New Data Set パネルで、以下の情報を入力し、Enterを押します。
※ここに記載がないものは、ブランクで問題ないです。
Name: `HERC01.TEST.PDS.LIB` →入力済
Record Format: FB
Logucal Record Length: 80
Physical Block Size: 3120
Volume Serial: WORK02 →入力済
UNIT: 3390
Allocation Space Units: C
Primary Space Quantity: 1
Secondary Space Quantity: 1
Directory Blocks: 10 →順次データセット作成時と違う点
Enterを押した後は、F9を押して、データセットをブラウズしていた画面に戻り、データセット名入力画面までF3で戻りましょう。
その後、Data set name prefixに先ほど作成したデータセット名を入力し、Enterを押しましょう。
Data set name prefix = HERC01.TEST.PDS.LIB
Volume serial numer = WORK02
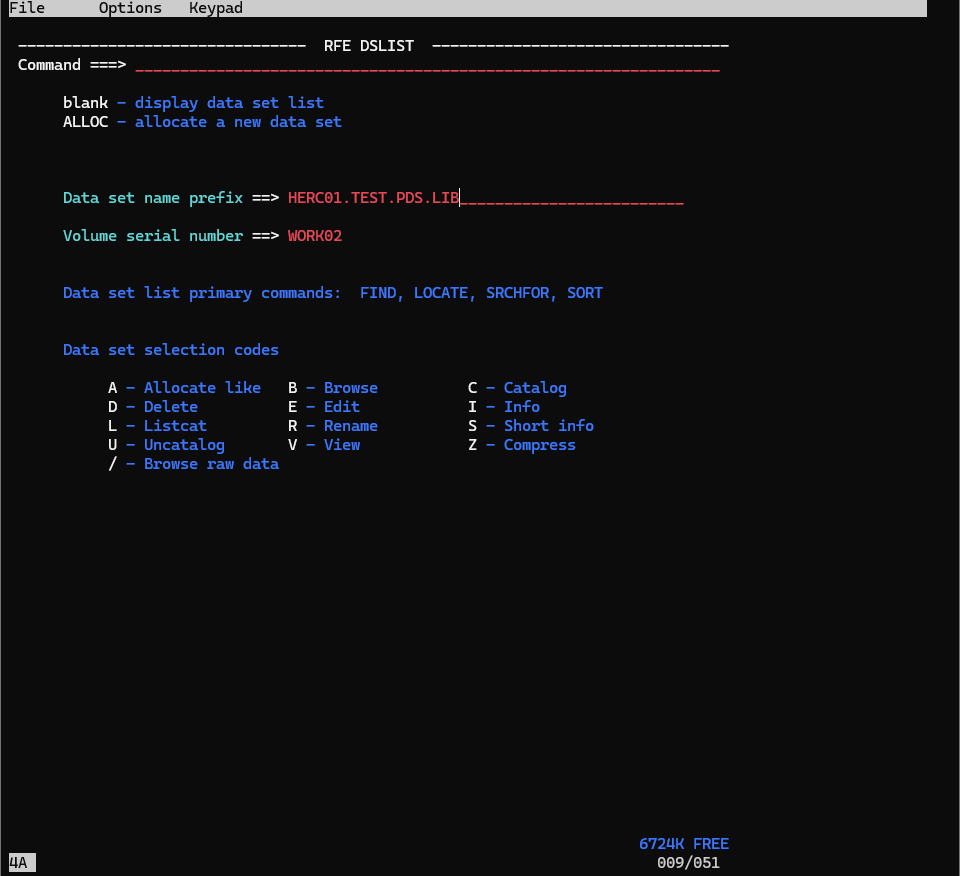
データセットが表示されたら、eを入力しEnterを押します。
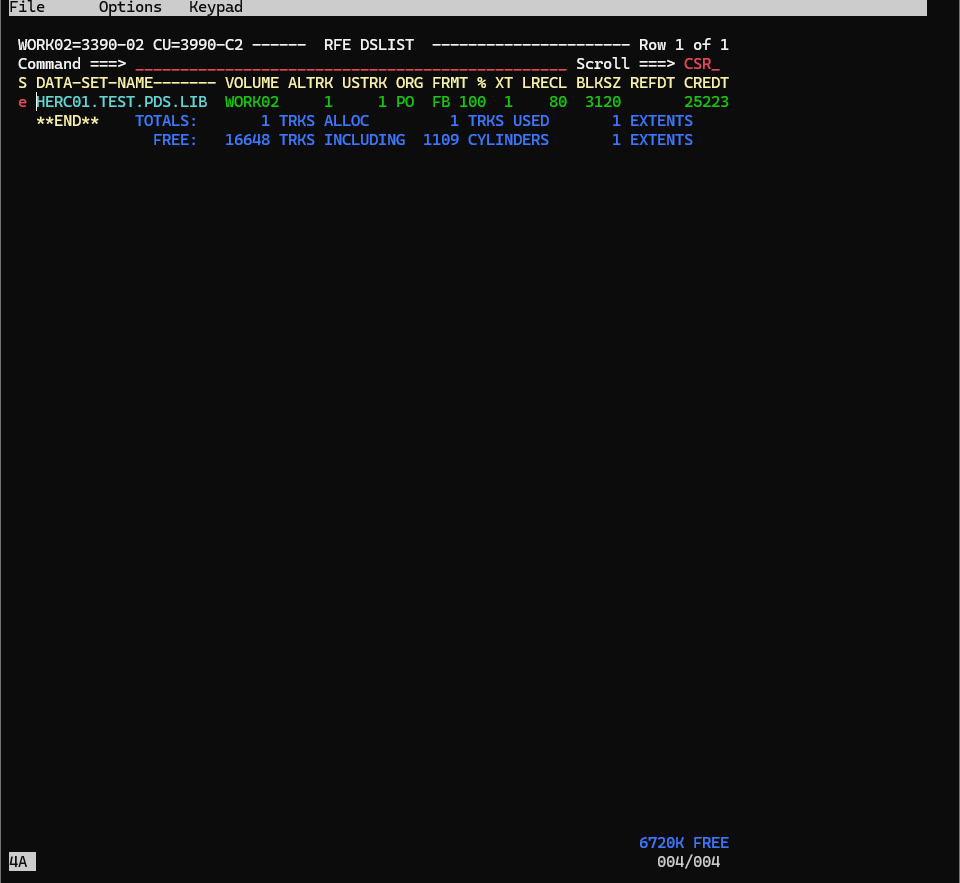
区分データセットの中には、まだ何も作成されていないので、以下のコマンドで、メンバーを作成しましょう。
S TEST01
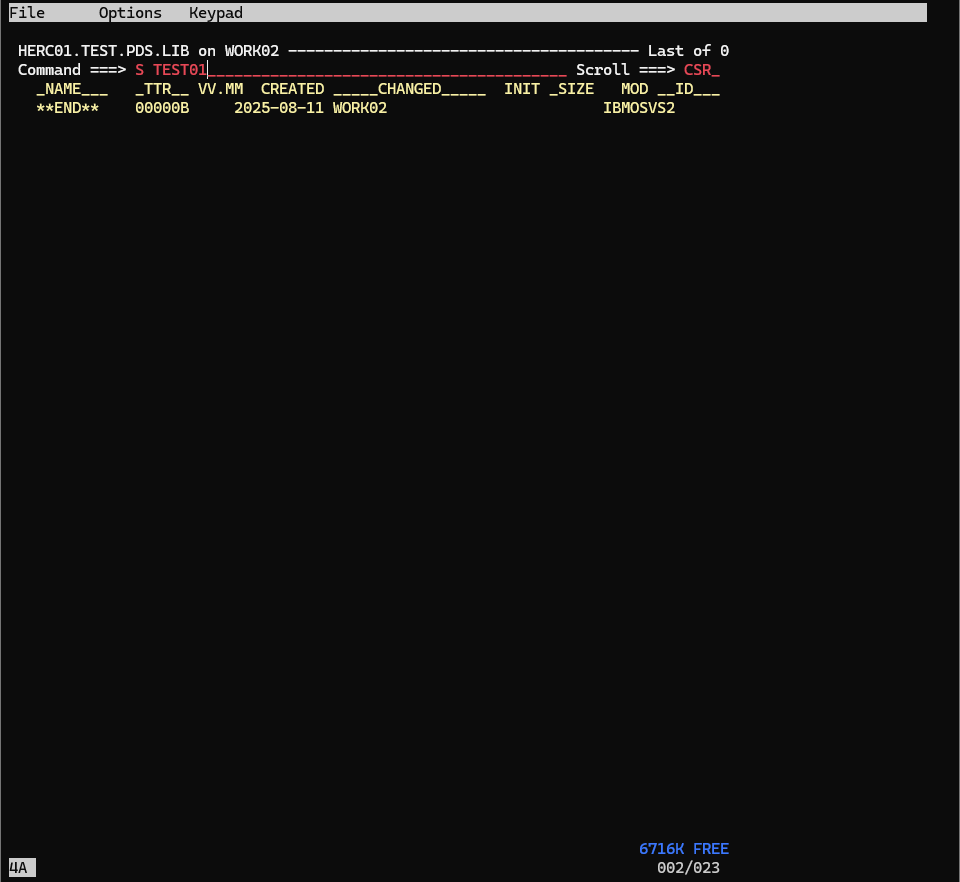
ここからは順次データセットと同様に適当に何か入力し、SAVEしてF3で抜けてみましょう。
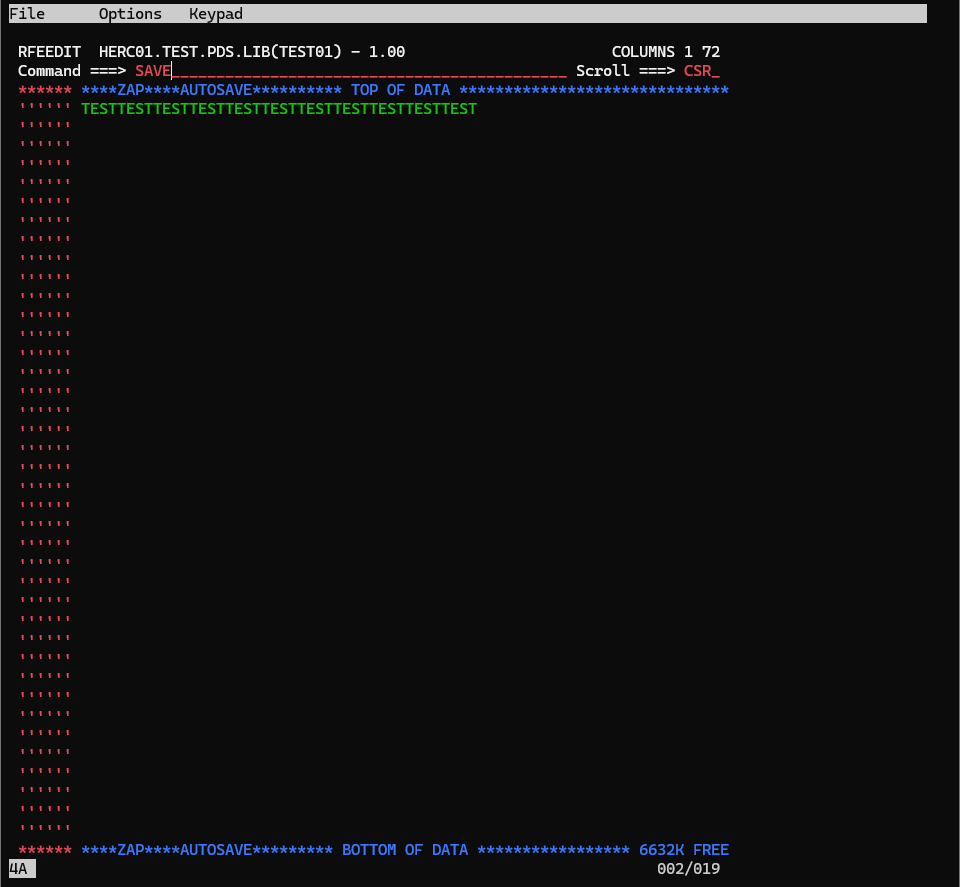
F3で抜けると、以下のような画面になります。
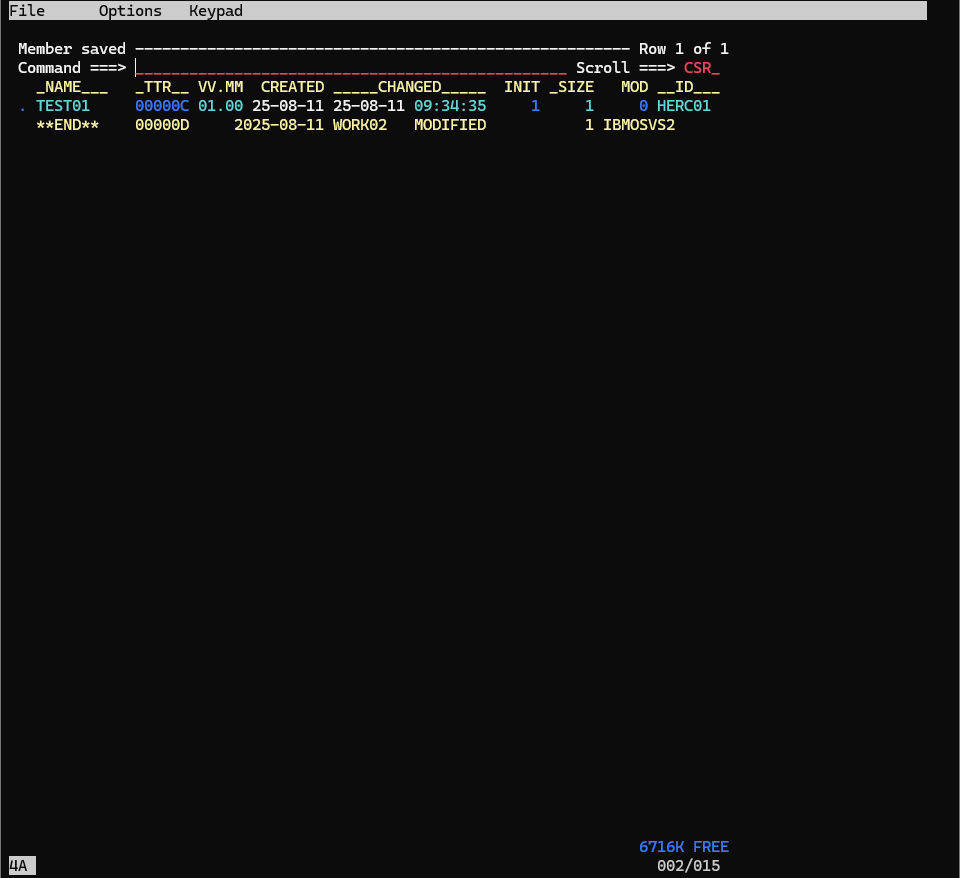
区分データセットの構造として、データセット内には、作成時に指定したDirectory Blocksの値が許す分のメンバーというものが作成できます。
Windowsで例えると、フォルダ(データセット)の中にファイル(メンバー)を作った。という状況です。
※歴史的には、例える順番は逆なのかもしれませんが...
以上が、順次データセットと区分データセットの作成です。
この後は以下の手順でシャットダウンしましょう。
ステップ6: シャットダウン
herculresコンソール画面で以下の手順を実施していきます。
/$p jes2
以下のメッセージが表示されればOKです。
$HASP000 JES2 NOT DORMANT -- SYSTEM NOW DRAINING
次に、以下のコマンドを入力します。
/z eod
その後、最後に以下を入力し、
quit
hercurlesが終了した旨のメッセージが表示されたらシャットダウン完了です。
HHC01427I Main storage released
HHC01427I Expanded storage released
HHC01422I Configuration released
HHC01424I All termination routines complete
HHC01425I Hercules shutdown complete
HHC01412I Hercules terminated
HHC00101I Thread id 00007b3cc150ecc0, prio 5, name 'panel_display' ended
HHC00101I Thread id 00007b3cb3fff6c0, prio 7, name 'timer_thread' ended
データセットの種類と詳細について
MVSにおけるデータセットについて
MVSでは、データセット(ファイル)をアロケーションした際に、以下のパラメータを指定しました。
Allocation Space Units: C
Primary Space Quantity: 1
Secondary Space Quantity: 1
これは、事前にアロケーションするデータセットの容量を指定しています。
Windowsなどでは、例えばテキストファイルを作成し何か文章を書いて保存すれば中身のデータに応じて容量が決まりますが、MVSでは事前にどれくらいのデータが格納されるかを把握しておいて、容量を指定する必要があります。
まず、Allocation Space Unitsについてですが、以下の3つのパラメータを指定可能です。
指定できるパラメータ
- Tracks:トラック
ディスク(記憶媒体)の物理的な円形トラックに相当する単位で、最も低い単位での指定方法。
ディスクの種類(Unitで指定した3390など)によって1トラック当たりのバイト数が違います。
3390では1トラック当たり約56,664バイトです。
1トラック=ゴロロムシBiteで覚えましょう
バイトへの換算例(3390装置の場合)
バイト数 = トラック数 * 56,664(バイト) - Cylinders:シリンダー
ディスク(記憶媒体)は丸いCDROMのような円盤が重なっています。
その円盤の同じ位置にあるトラックが15個集まると、1シリンダーになります。
この指定方法もディスクの物理構造に基づいた単位で、トラックよりも大きな単位で容量を管理できます。
バイトへの換算例(3390装置の場合)
1シリンダー = 15トラック * 56,664(バイト) = 849,960(バイト) - Blocks:ブロック
ディスクの物理構造に依存しない、論理的な単位です。
データはブロックと呼ばれる単位で保存されます。
ブロックサイズはユーザーが指定します。
データセットのレコード形式によって最適な値が異なります。
バイトへの換算
バイト数 = ブロック数 * ブロックサイズ
次に、Primary Space Quantityについてですが、これはアロケーションする際に最初に確保するデータ容量を指定するパラメータです。です。
とりあえずは、この指定分のデータ容量を確保する、と覚えておきましょう。
次に、Secondary Space Quantityについてですが、これは例えばデータセットに対して何かしらの書き込みを行う際に、Primary Space Quantityで指定した容量を超えた場合に拡張する容量を指定するパラメータです。
この容量が拡張される事象を"エクステント"と呼びます。
エクステントは、15回までしか行われないため、容量の見積もりは慎重に行いましょう。
順次データセットについて
順次データセットは、データを1つの連続した流れとして格納するシンプルな形式です。
- 構造:データは先頭から末尾に向かって、順番に記録されます。レコード間の区切りやインデックスは存在しません。
- アクセス方法:データを読み書きする際は、常に先頭から順次アクセスします。特定のレコードに直接ジャンプすることはできません。
例えば、100番目のレコードを読みに行くときは、1~99番目のレコードを順番に読み飛ばす必要があります。 - 用途:大量のデータを一括で処理する際に重宝します。
ログファイル、レポートの出力、トランザクション履歴などに使用します。
バッチ処理で多く利用されます。
区分データセットについて
複数の順次データセットを1つのデータセットにまとめた形式で、Linuxでいう「ディレクトリ」やWindowsでいう「フォルダ」のような形式です。
- 構造: 区分データセットは、ディレクトリ部とメンバー部の2つの部分で構成されます。
- ディレクトリ部: 各メンバーの名前と、データが格納されている場所(アドレス)の情報を管理します。
- メンバー部: 実際にデータが格納されている部分で、各メンバーは内部的には順次データセットと同じ構造を持っています。
- アクセス方法: ディレクトリ部を利用することで、特定のメンバーを直接指定してアクセスできます。
これにより、個々のメンバーを効率的に読み書きできます。ただし、メンバー内のデータは順次的にアクセスされます。 - 用途: プログラムのソースコード、JCL(ジョブ制御言語)、マクロ、ロードモジュール(実行可能プログラム)など、複数の小さな関連ファイルを管理するのに非常に便利です。
メンバー単位での管理が容易なため、開発環境で多用されます。
今回作成した区分データセットをツリーで表すと、以下のようになります。
HERC01.TEST.PDS.LIB(データセット)
┣TEST01(メンバー)
┣TEST02(メンバー)
・
・
・
さいごに
今回はデータセットをアロケーションしてみました。
古のファイル作成、いかがだったでしょうか?
自分は最初事前に容量を指定してデータを格納するガワだけ作成してデータを入れていく、という概念に戸惑いましたが、逆にこの時代から今のオープン系などのOSが進化して便利になっただけなのだ、と後から気づきました。
MVSは継承の世界のため、昔のパンチカード時代に作られたものをずっと使い続けるための仕様、と考えると感慨深いものがあります。
そして、それらを自宅でエミュレートし、歴史を追っていけるとはすごい時代になったものです。
この令和の時代にMVSを触ることになった方の参考になれば幸いです。
Comments